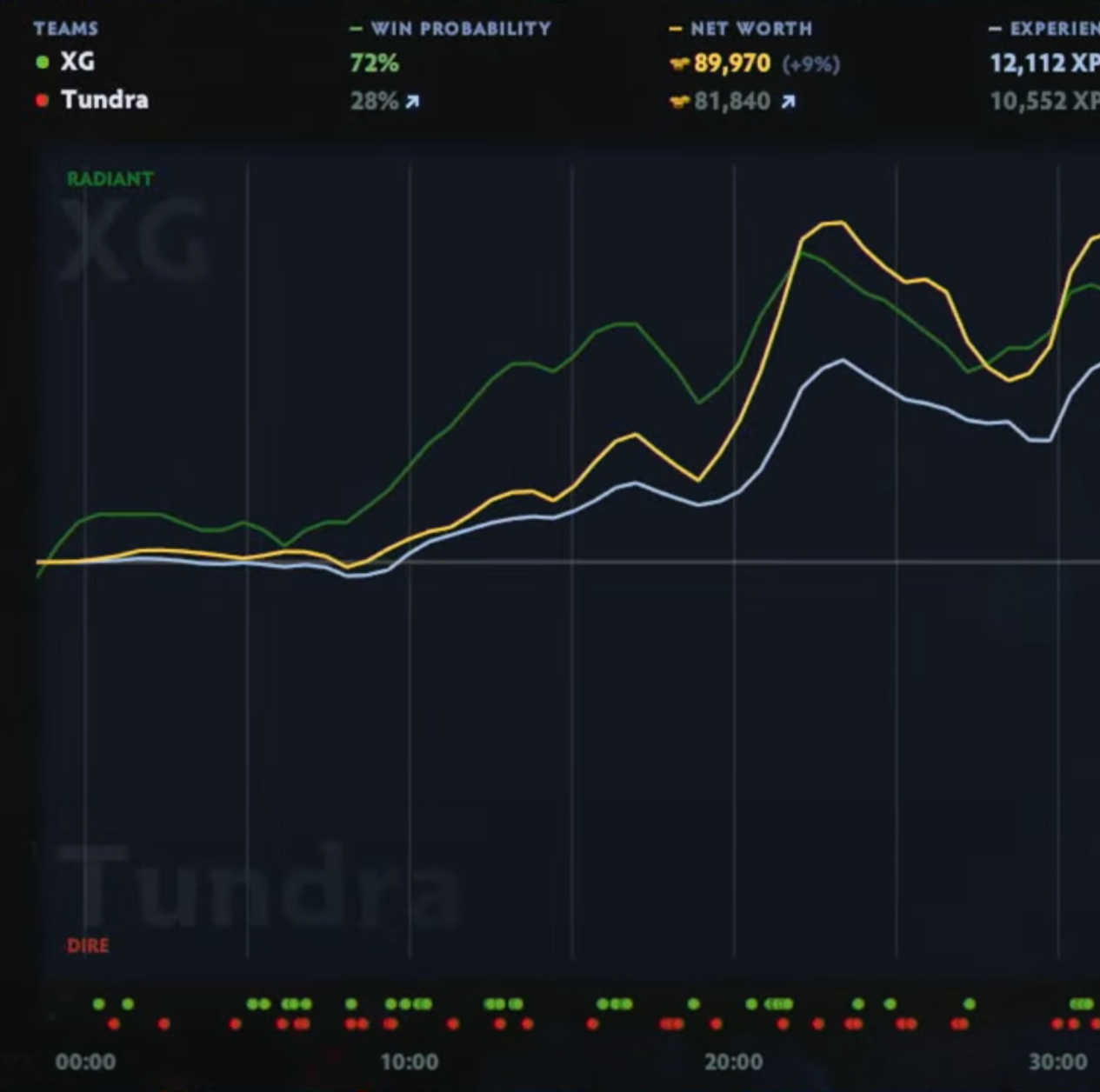
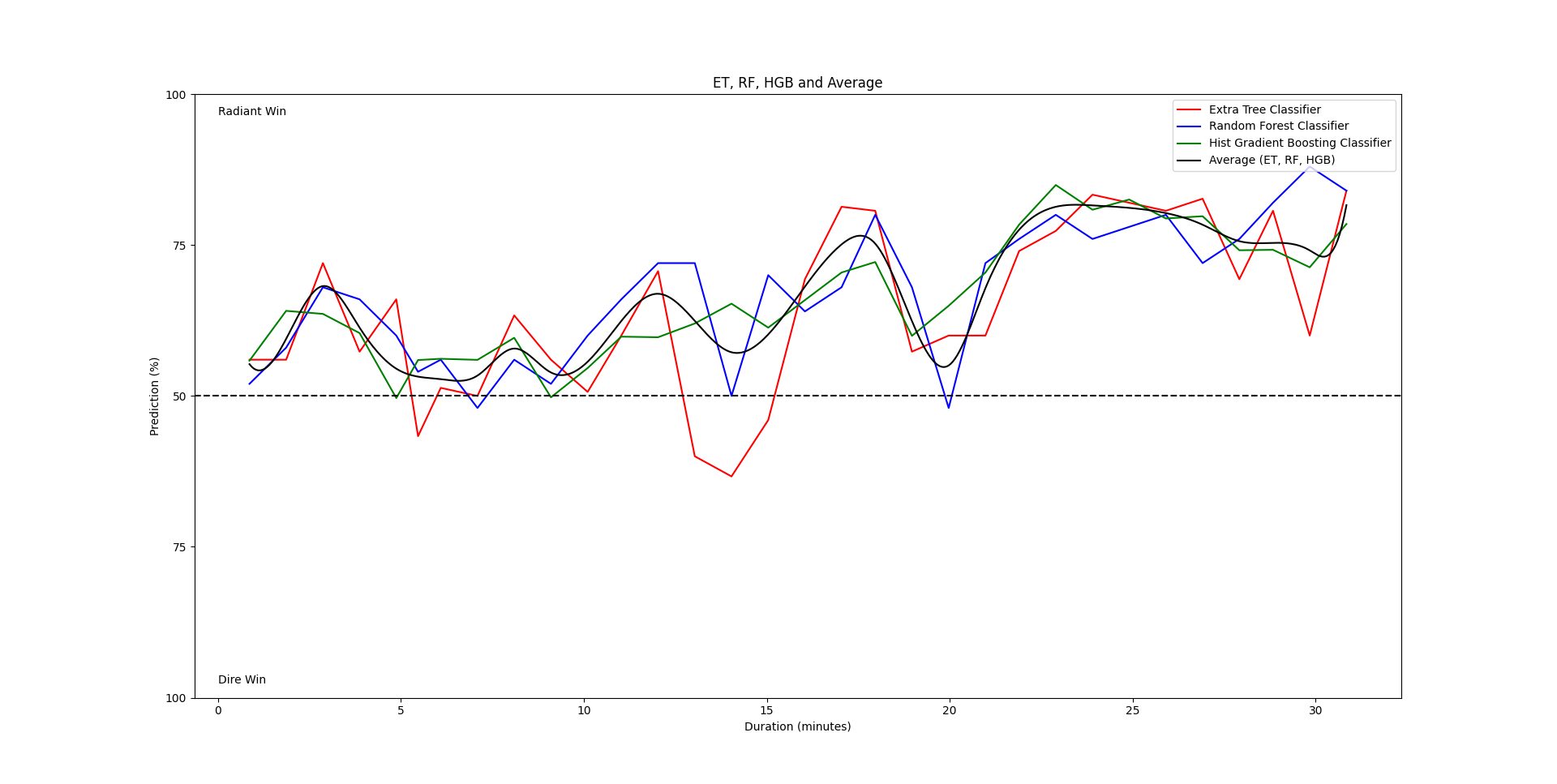
Dota 2 Data Science Pipeline (open source)
View on GitHub:
github.com/sukhrobyangibaev/thesis-pub
This open-source project is a modular data science pipeline designed for large-scale analysis and predictive modeling of Dota 2 matches. It streamlines the process from raw data collection to feature engineering and model evaluation, making it ideal for esports analytics, academic research, and competitive gaming communities.
The pipeline supports end-to-end workflows: scraping match data from public APIs, transforming and embedding features (heroes, items, in-game stats), and training machine learning models to predict match outcomes or player performance.
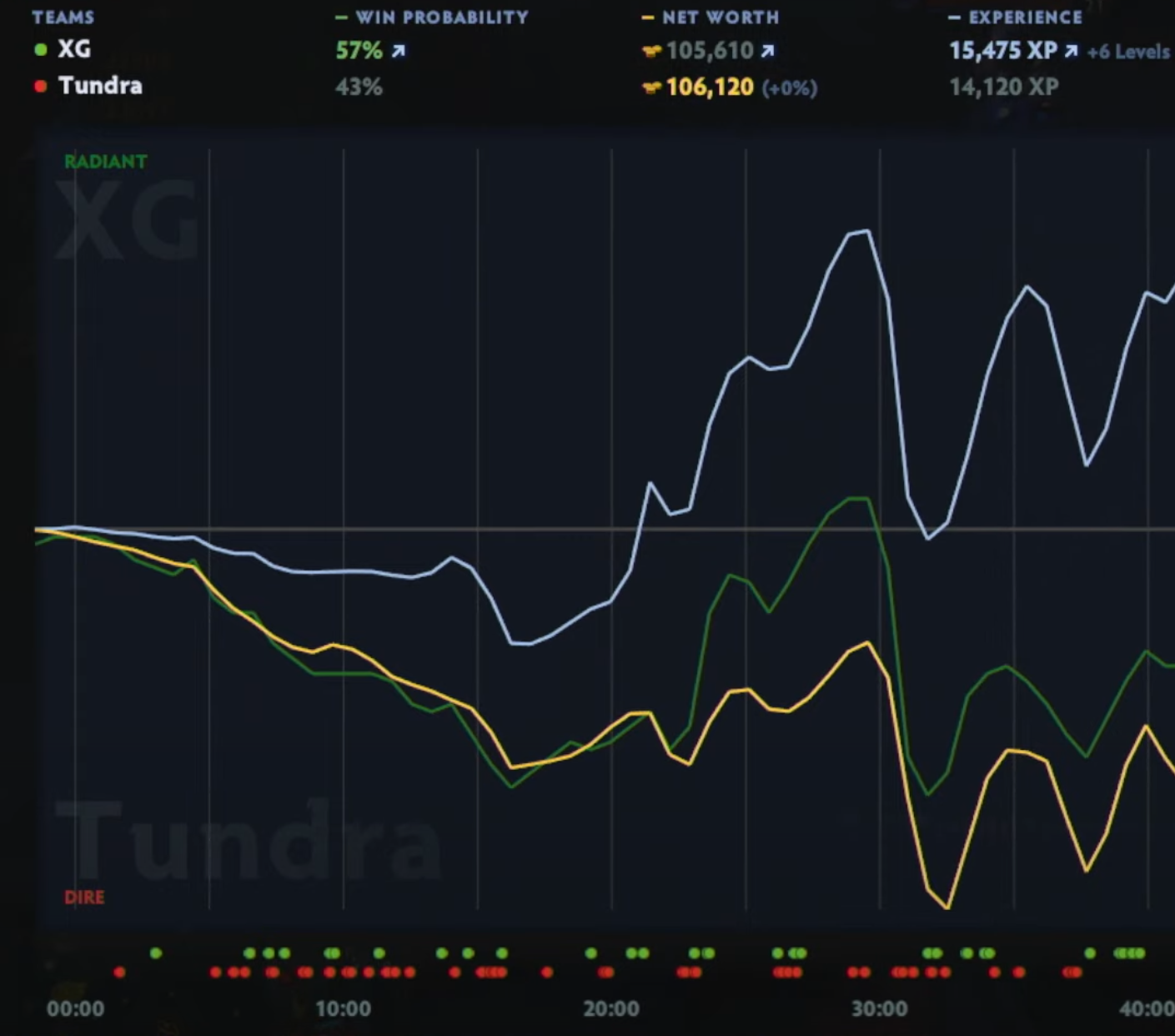
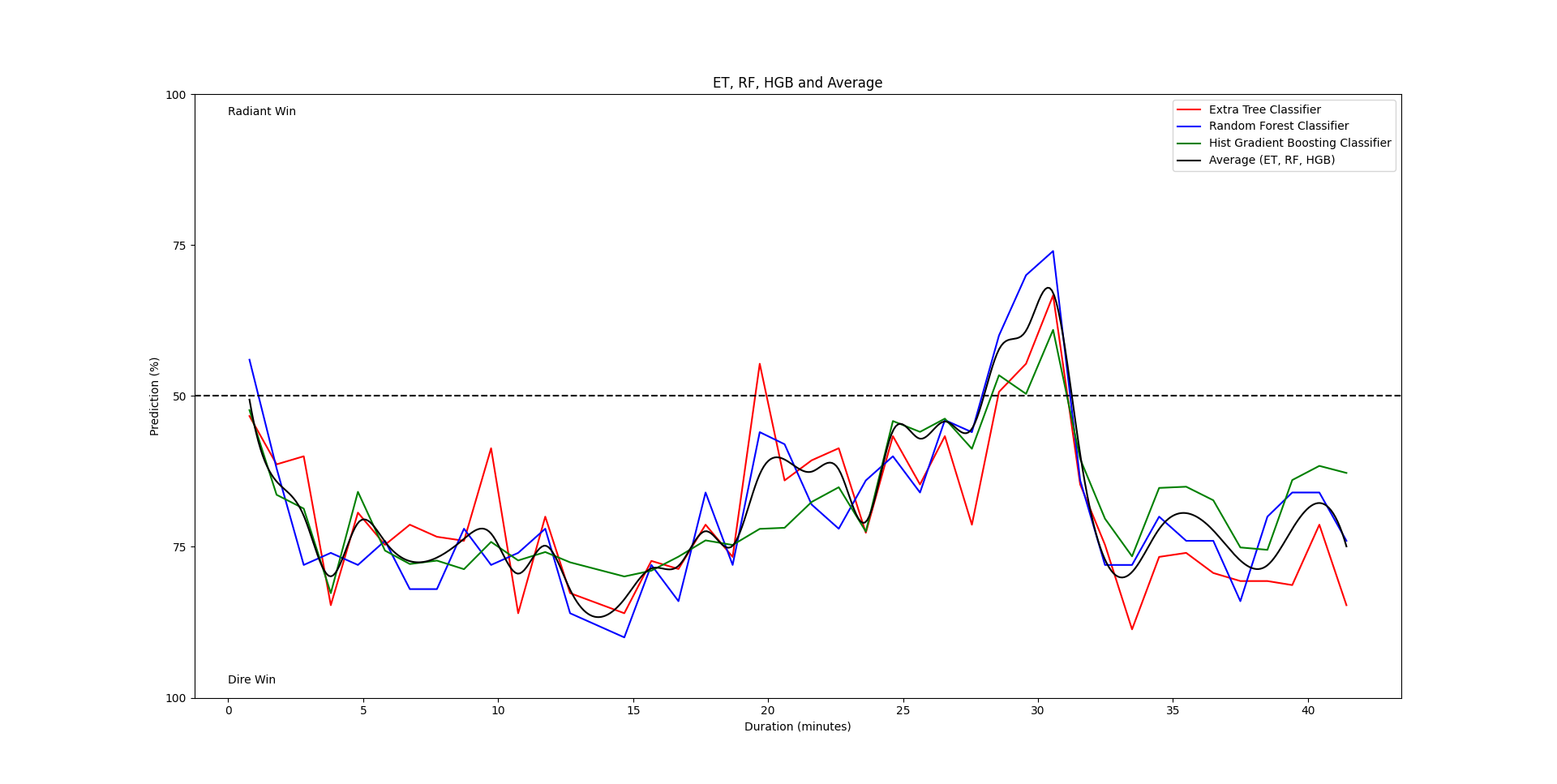
Key Features
- Automated Data Collection: Scripts for scraping match, hero, and item data from OpenDota and Steam APIs, with support for periodic updates and custom queries.
- Flexible Preprocessing: Tools for cleaning, merging, and transforming large CSV datasets (hundreds of thousands of matches), including handling missing values and outliers.
- Feature Engineering: Embedding modules for heroes and items, winrate calculations, and advanced in-game metrics extraction.
- Experiment Management: Organized directory structure for storing raw data, processed features, experiment results, and trained models.
- Model Training & Evaluation: Ready-to-use scripts for training and benchmarking various machine learning models (e.g., Random Forest, Gradient Boosting, Adaboost, CART, etc.) with scikit-learn.
- Visualization: Built-in support for generating plots of feature importances, model scores, and dataset statistics for analysis and reporting.
Technical Architecture
- Backend: Written in Python, leveraging
pandasfor data manipulation andscikit-learnfor machine learning. Modular scripts for each pipeline stage (data scraping, embedding, training). - Data Storage: CSV files for raw and processed data, organized by time intervals and experiment type. Results and models are saved for reproducibility.
- APIs: Integrates with OpenDota and Steam APIs for up-to-date match and player data.
- Experimentation: Supports rapid prototyping and comparison of different feature sets, model architectures, and preprocessing strategies.
- Documentation: Markdown files for each experiment and model, with notes, results, and visualizations.
Example Workflow
- Data Collection:
Use provided scripts to scrape match, hero, and item data from OpenDota/Steam APIs. - Preprocessing & Feature Engineering:
Clean and merge datasets, generate embeddings, and compute winrate statistics. - Model Training:
Train machine learning models on processed datasets, evaluate performance, and save results. - Analysis & Visualization:
Generate plots and markdown reports to interpret model results and feature importances.
Technologies Used
- Python 3
- pandas
- scikit-learn
- requests (for API access)
- matplotlib / seaborn (for visualization)
- dotenv (for environment configuration)
This project demonstrates how open-source tools and modular pipelines can accelerate esports analytics, enabling reproducible research and advanced predictive modeling for Dota 2 and similar games.